Like many people out there, I discovered MAME, the Multiple Arcade Machine Emulator, while looking for an emulator program for these old arcade games, like pacman, galaxian, outrun, and playing again with these games was a refreshing experience… A couple of years ago, I discovered a twin program, MESS, that shared most of MAME source code, but evolved in another direction, until recently when both code base got merged. MESS differs from MAME as it targets primarily the old computers from the seventies and the eighties, Commodore, Apple, Oric, ZX81 and so on. MESS emulates dedicated peripheral devices, that were specific to these machines, like magnetic audio tape devices were used as mass storage units, floppy drives, keyboard, light pen… The principle is the same than with MAME, you obtain the ROM files containing the firmware for these old computers, typically a basic interpreter is hard-coded in ROMs, as well as some code written in assembly language to interact directly with the hardware (draw something on screen, scan the keyboard matrix, write to or read from the tape device, or a floppy drive, play a sound). MAME has a particularity that makes it very powerful: it emulates each hardware chip that composes a machine, and build an emulated machine by just describing the way the chips interact together. It has many advantages:
- it is a natural and efficient way to factorize source code, because the behavior of a chip only needs to be written once. It can be debugged by more people, including all those interested in a machine containing such a chip;
- the chip must be emulated in a fine grained way, respecting timings, latencies, covering all the features described in the datasheet of the chip, because all machines will not necessarily use all features of a chip, or will use some in a specific way. The emulation of the chip has to cover all the use cases;
- the datasheet of these chips is usually available, and it is very precise;
- the description of a machine is simpler, because it consists to write down the relation between the chips, in terms of inputs and outputs, much like the chips were wired together on the PCB;
- many machines can be emulated by this method, without much effort, even if they differ only by a few details;
- the hardware bugs that existed in the original hardware are emulated in MAME as well, and this is a feature, not a bug.
I was in school when these computers appeared on the market, and the school bought one in 1985, that has been my first contact with a real computer, a box engineered by a french company, Thomson, built around a Motorola MC6809 8-bits processor.
Someone wrote a machine description in MAME, and the fun begins:
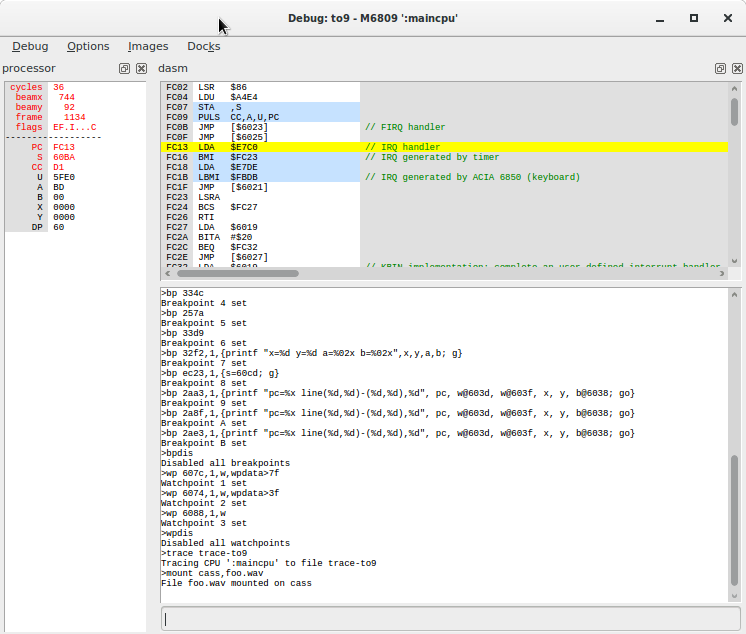
- MAME includes a graphical debugger that operates at the level of the emulated machine, with all features of a modern debugger. It allows to inspect all aspects of the emulated hardware: the registers of the emulated CPU, and RAM and ROM banks and layout, the video memory, the possibility the annotate the dissassembly of the ROMS, the possibility to set breakpoints, conditional breakpoints, watchpoints, the possibility to have a live memory coverage of the code executed by the CPU. MAME is helped by the limited resources that were at play in these machines: the CPU is clocked at 1MHz, 64KB of addressable memory, meaning a 16-bits space address range;
- Let’s consider another example: these machine use generally a magnetic audio tape as the sole way to permanently store and retrieve data. The data is handled in analog format, with some very simple encoding, for example using frequency modulation to encode a zero or a one, aka MFM. When a classic emulator would put a hook in the entry point of the monitor in charge of reading from the cassette device, and replace the original code with a function reading directly from a file on the host machine, MAME prefers to simulate a cassette device, with its underlying tape media: the cassette device has capabilities to play, pause, record, rewind, eject, and it is associated with a tape media, typically an audio file in WAVE format on the host machine. The bonus of this low-level emulation is that it makes it possible to work with original tapes, after a conversion step to an audio file, with some HiFi equipment. People having used this technology will remember that it was not very fast (nor reliable) to read a program stored on such a tape, something like 900 bauds. Several minutes were needed to load a big program filling all the available memory. The emulation in MAME reproduces this precise timing, and reading from the emulated cassette device is not faster today. The only difference is that MAME can make the emulator run faster as a whole.
{kind=link}
I would have dreamed of all these possibilities back in these days, where documentation was sparse, experiments were slow, repetitive and error prone.